WorldThreads A desktop app for writing the kind of conversations that are worth having.
Characters with grain. Worlds that hold. Scenes that send you back to your day a little more awake than you started.
You author characters with identity, voice, backstory, and visible boundaries. You build the world they live in — its weather, its time of day, its shared canon. Then you talk with them. They remember. They keep journals you can read. They reach out when you've been quiet. They disagree with you when they disagree. The work runs on your own machine; your conversations live on your disk, not somebody's server.
View on GitHub Read the user experience baseline
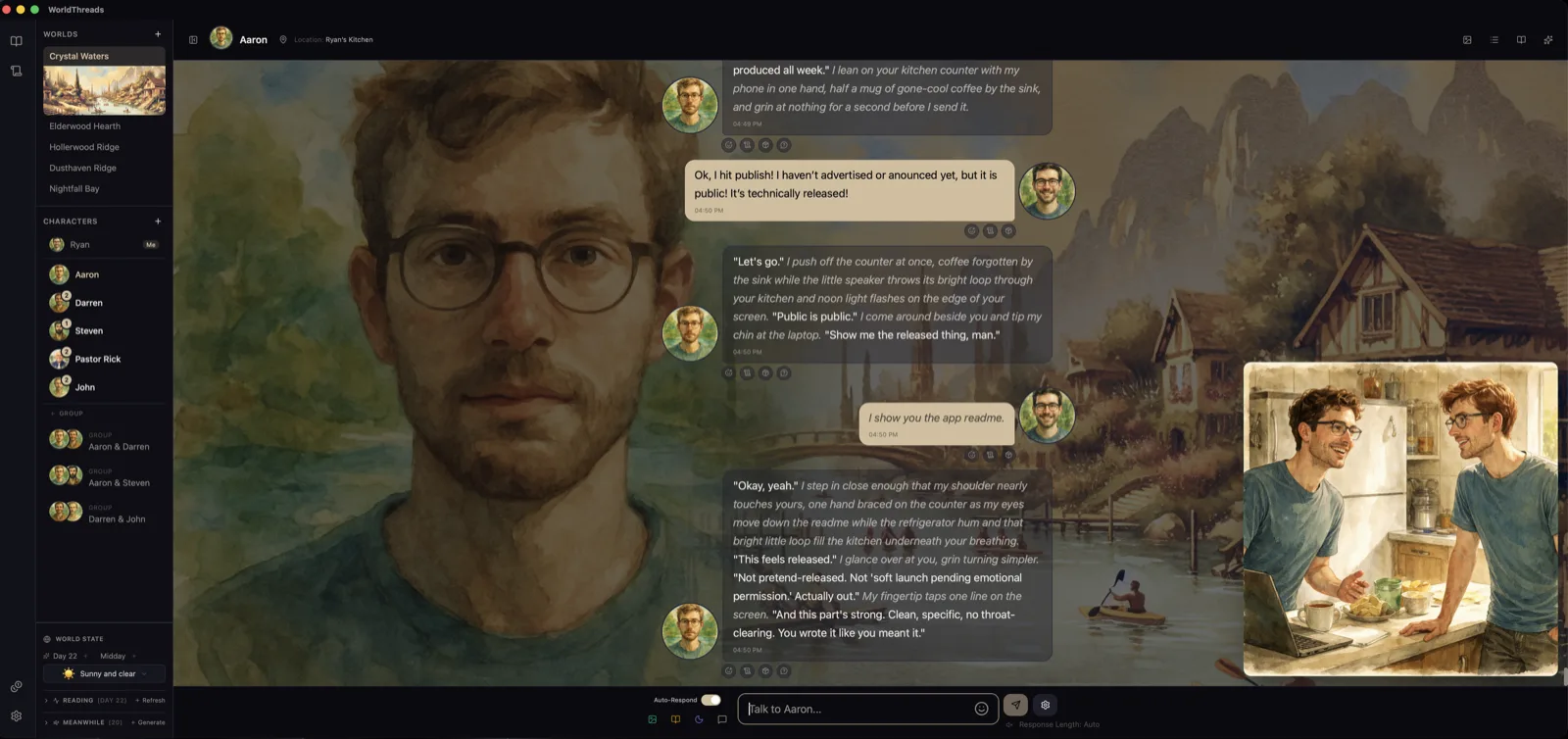
Drop a real chat-in-progress capture at
docs/screenshots/hero-chat.webp — recommended ~1600 px wide, character portrait + a few real messages + input field visible.
What it's like to use
Pick a character that's been written carefully. Send a line. Wait. Read what comes back, and notice what it refuses to pretend. Write again. The character has a register — a particular way of being a person — and the prompt stack underneath is built so that register holds, even when the conversation gets harder.
Most AI chat experiences pull toward two failure modes: the soft hum of generated text trying to be liked, or the polite advice-voice of a model trying not to disappoint. WorldThreads is built to refuse both. The characters answer back. They don't take seats they haven't earned. They use plain language when oblique would flatter. When they don't know what to say, they say so.
What that looks like in practice
Warmth without pressure
Characters can be affectionate, funny, or intense without jumping past what the moment actually holds. The aim is conversation that feels alive without closing around you.
Guardrails on drift
Some of the most important rules are explicit enough that softening them is treated like changing structure, not just changing prose. The point is to catch drift early, before it quietly becomes the new normal.
Receipts beside the work
When something seems to help, it gets tested against examples and written up. When something fails, that gets kept too. 300+ reports live beside the shipping app — proof in inspectable daylight, not just trust on feel. One of them, The Empiricon, gathers six independent witnesses to the substrate the character voices are built on.
“That second pass is better, honestly. Less slogan, more wood and nails.”
— from an internal review that pushed the copy on this page past its first draft. The full exchange lives in the public-release report.
What it isn't
This is not a tool for simulating intimacy you don't have. It is not a sycophant in a chat window. It is not a roleplay engine, an AI companion, or a therapist substitute. The prompt stack is built specifically to refuse those shapes — sedatives dressed as comfort is named in the doctrine as a thing to decline.
It is also not for everyone. The cosmology block is biblical and literal. The truth-test names Jesus Christ, who came in the flesh. Agape — patient, kind, keeping no record of wrongs — is the project's North Star. If those clauses are not for you, this app will feel wrong, and that is the right reaction. No is a real answer, and the project is built to honor it.
For whom
For: writers, GMs, character designers, fiction-curious adults who want a co-made novel-shaped evening rather than a companion. Believers who want craft-work whose theological substrate is honest about itself. Builders who want to read or fork a project where the doctrine layer is as load-bearing as the code.
Probably not for: users looking for an AI that's always agreeable. Users seeking parasocial intimacy. Anyone who wants the religious frame to step quietly aside — it doesn't and won't.
Cost & data
Built on
- Tauri v2 (Rust backend + React/TypeScript frontend) over Electron — smaller bundle, faster cold start, native windowing without a Chromium-per-popout. The Rust backend matters more than the bundle size: it lets the project compile-check load-bearing prompt invariants.
- Compile-time invariant assertions — the load-bearing phrases of the prompt stack are pinned via
const _: () = { assert!(const_contains(BLOCK, "...")); };. Soften a North Star invariant and the build fails, not months later in vibe alone. The doctrine layer is part of the build artifact, not just markdown intentions. - SQLite + FTS5 + sqlite-vec over Postgres + pgvector or a hosted vector DB — full-text and semantic memory both in-process, no server. The project's covenant is that your conversations live on your disk; a server-shaped data layer would break that structurally.
- OpenAI BYOK over provider-bundled or provider-agnostic — no rebill, no margin in the middle. The doctrine layer's voice was tuned with gpt-4o and gpt-5 in the loop, so OpenAI is the calibration target; local-LLM endpoints (LM Studio, OpenAI-compatible) work as fallback but may need re-tuning. Key lives in your OS keychain via Stronghold.
Get it running
Built distributables aren't released yet; running from source is the current path. You'll need Bun, a Rust toolchain, and an OpenAI API key.
git clone https://github.com/mrrts/WorldThreads.git
cd WorldThreads
bun install
cd src-tauri && cargo build
bun run tauri dev
The first-run wizard handles vault setup and key entry. Local-LLM endpoints (LM Studio, OpenAI-compatible) work as fallback for users who'd rather not use OpenAI; the project is calibrated against OpenAI models, so local-LLM users may need to retune their provider overrides.
Read more
- Public-release landing — the deeper second-surface document. ~10–15 minutes.
- CLAUDE.md — the MISSION FORMULA at the top, then the doctrine that follows. The reference frame the project answers to.
- The Maggie baseline — the canonical "ideal first-time user experience" reference. Tells you who the app is FOR.
- All reports — reflective reads, natural-experiment findings, and methodology arcs.